

Overview:
As our group final project for Analytics Edge at MIT Sloan we decided to try our hand at building an algorithm to profitably bet on NBA games. What we found is that by using a rich dataset and increasingly more complex models, we could generate an edge over the sports books in Vegas. If deployed, we understand that all advantages in competitive markets tend toward zero in the medium to long run, but in the short run represents a profitable opportunity to use analytics in search of returns.
Data Collection:
In all model building exercises, special care should be taken on the all important data collection phase. Garbage in, garbage out is a popular refrain for a reason. In our project, a majority of our time was spent in this phase. We needed to ensure that we had data that we could both trust and would be available to us prior to tip off.
We ultimately settled on compiling three types of data:
Team / game specific data
Here we were able to gather data on every NBA game played from the 2003 through 2019 season including the teams, home and away signifiers, number of points, assists, and rebounds for each team, and average field goal and three point percentages
Individual player data
Additionally, we were able to glean starting lineups and incorporate a one-season lagged ESPN PER rating for those players to create fields like Avg. PER and Max PER for a team in each game. This gave us a sense of the quality of the starting line up for a team in a game and is information you would have prior to tip off.
Vegas odds data
Finally, we had historical data on Vegas money-line odds for each game from 4 separate sports books, in each game, we imported the best line for the home and the away team that we would have bet on
Finally, while we had rich data for many seasons, we limited our training and test data to the 2014 through 2018 seasons. This was for a multitude of reasons but the most compelling being that scoring has constantly increased over the past ~2 decades and that sports books and their odds have become increasing more accurate. To compensate for these trends we decided to use more recent data.
In the end, we ended up with a dataset of 5,430 regular seasons games with 57 unique variables available to use in our model.

Variable distributions
Models & Methodology:

Graph of AUC of our XGBoost Model
While we ultimately attempted three modeling approaches, our most successful was, not so surprisingly, XGBoost. Using XGBoost we were able to get an accuracy of 93.8% as measured by AUC (shown to the left)
We trained our model using the 2014, 2015, and 2016 seasons and tested it on the 2017 and 2018 seasons.
When we ran our model with rules set up to make money line bets on each game where the confidence in the outcome was within 10% of either 0 or 1 we produced a net profit of $429K on $1,024K in risked capital over the two season or a 41.9% return on risked capital.
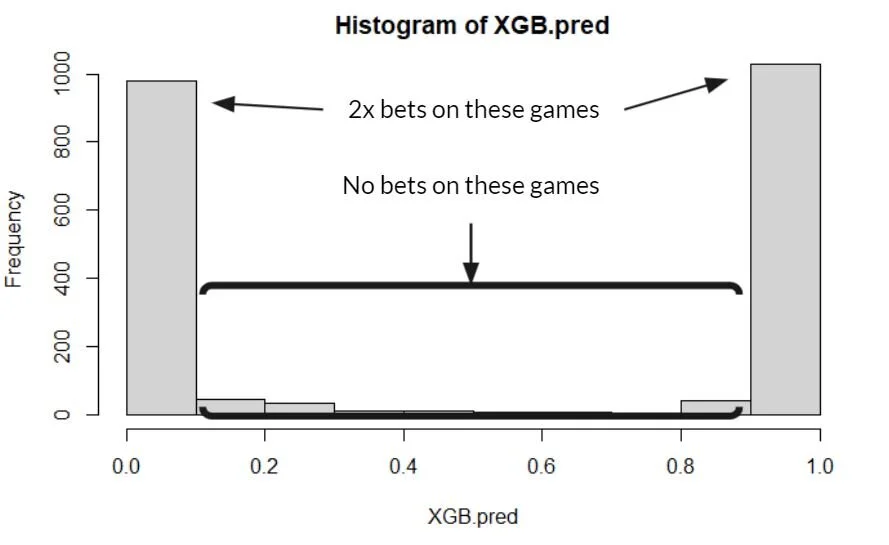
Simplified betting rules for the model
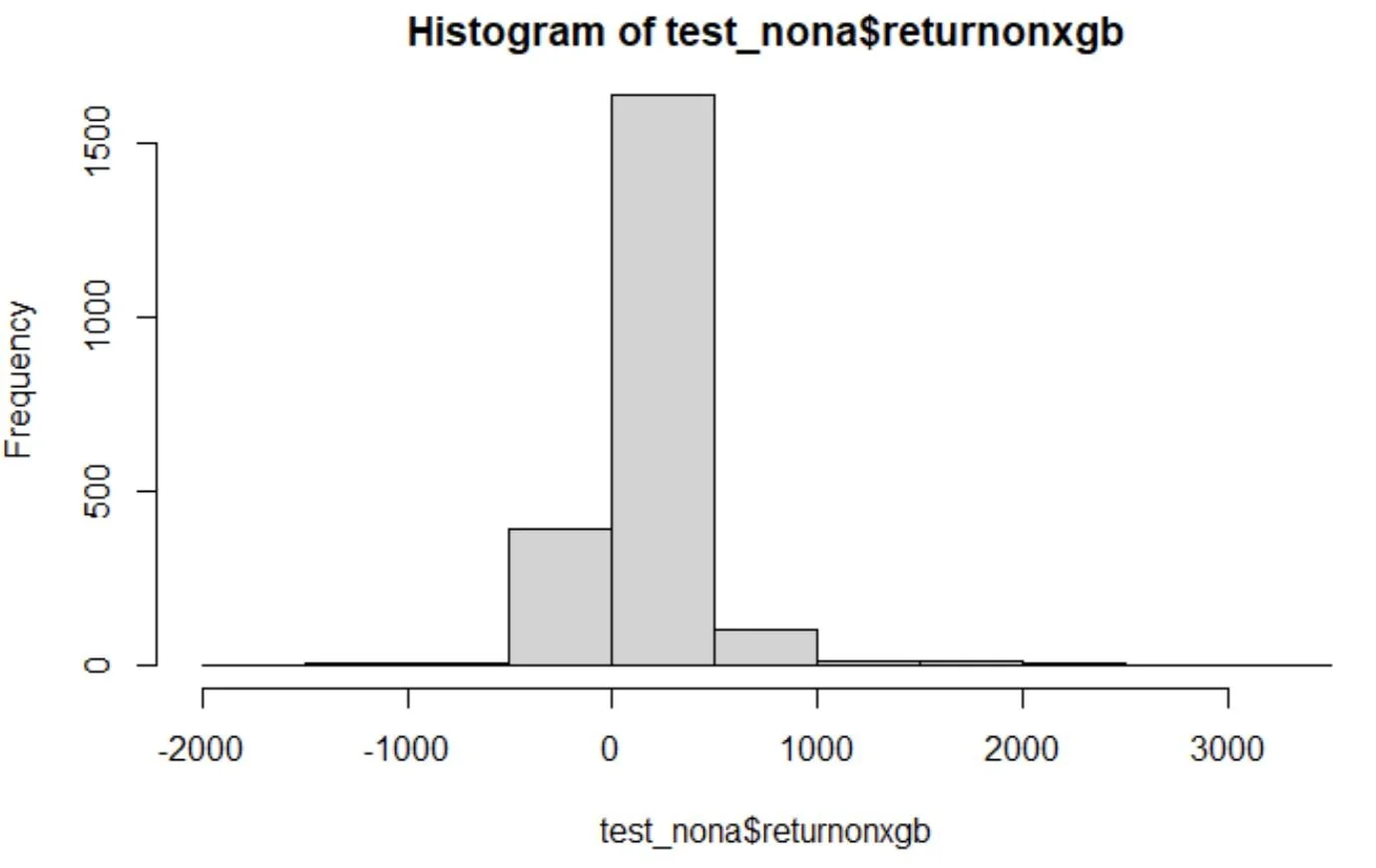
Distribution of returns on an individual game basis